Customize how field values are stored and queried in Solr with Sitecore 8
The default configuration for Solr with Sitecore 8 will happily find and index all of the data in your fields using the dynamicFields defined in the schema file.
Here is an example of a dynamic field configuration for a text field.
<dynamicField name="*_t" type="text_general" indexed="true" stored="true" />
Text fields are defined in the Sitecore.ContentSearch.Solr.DefaultIndexConfiguration.config **file and Sitecore field types of **“html|rich text|single-line text|multi-line text|text|memo|image|reference” are defined as text field types and processed as dynamic fields of type text when they are indexed by Solr
<typeMatch typeName="text" type="System.String" fieldNameFormat="{0}_t" cultureFormat="_{1}" settingType="Sitecore.ContentSearch.SolrProvider.SolrSearchFieldConfiguration, Sitecore.ContentSearch.SolrProvider" />
The default configuration for the Solr dynamic fields use the text_general Field Type and their language variants for the other languages e.g. text_de and these Field Types use the solr.StandardTokenizerFactory that splits the text field into tokens, treating whitespace and punctuation as delimiters. An example from the documentation :-
In: “Please, email john.doe@foo.com by 03-09, re: m37-xq.”
Out: “Please”, “email”, “john.doe”, “foo.com”, “by”, “03”, “09”, “re”, “m37”, “xq”
This is how the data looks in Solr when a field is processed by the StandardTokenizerFactory
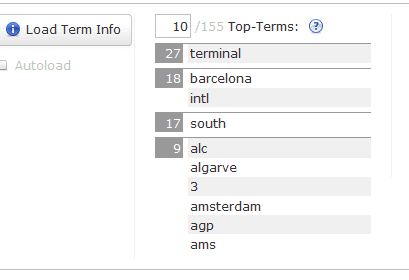
But what if you do not want the field value split in to tokens? Well that’s pretty straight forward as well…
If you wish to have more control over how the fields and their values are indexed and queried in Solr you can take advantage of Tokenizers and Filters.
In your schema.xml file for the Solr core you wish to modify add a new field definition before the list of dynamic fields, the field name should be as it would be defined in solr for example.
<field name="your_field_name_here_t" type="lowercase" indexed="true" stored="true" />
Here I have used the lowercase Field type defined in the schema file as :-
<!-- lowercases the entire field value, keeping it as a single token. --> <fieldType name="lowercase" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.KeywordTokenizerFactory" /> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> </fieldType>
The key change is the use of the KeywordTokenizerFactory this change means the field will be stored in the index and queried as the entire field value.
If you make changes to the schema.xml file you will need to restart your solr instance and re-index the core you have made changes to. Once this is complete you can use the schema browser for solr http://localhost:8080/solr/#/{your core name}/schema-browser and view the newly defined field to see you changes, notice the Field Type now shows as lowercase _and the **Index Analyzer** and **Query Analyzer** have changed, use the **Load Term Info_** button to see the changes to the values store by Solr
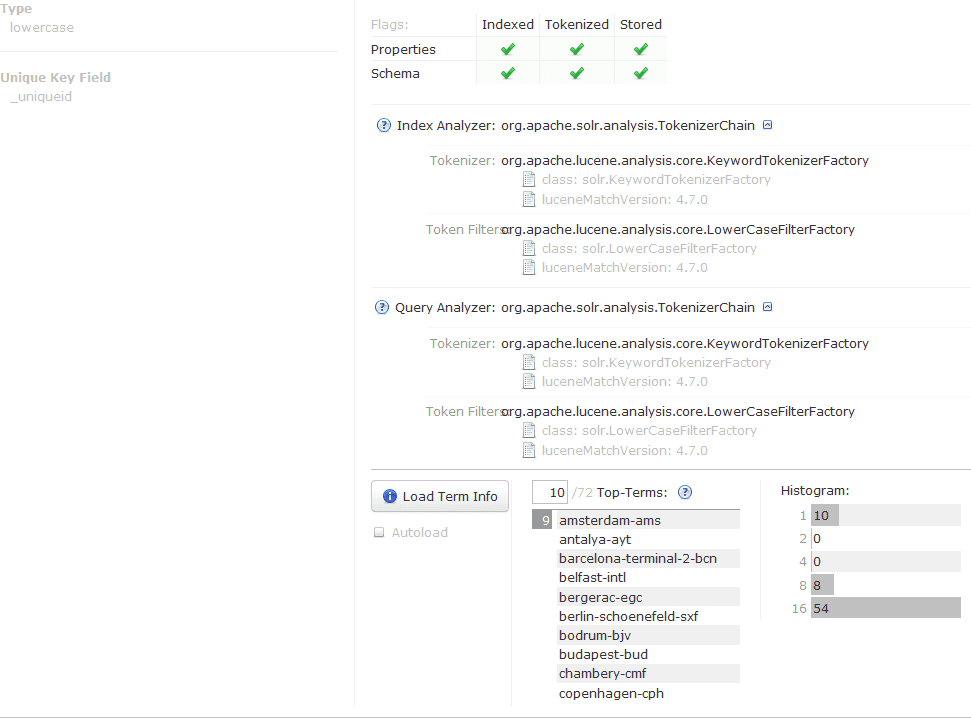
Filters and Tokenizers provide a powerful way to manipulate the data stored and queried through Solr.